IT Enterprise Monitoring Strategy
Introduction
In today’s world business services are transaction-based, application-intensive and end-user directed. IT people have to effectively manage several components like networks, servers, databases, web services, storage and applications. Everybody is seeing these components as independent entities and having their own Silo monitoring strategy. So in almost all of the IT Enterprises, when a problem arises, analysis takes a long time so the Mean-Time-To-Repair (MTTR) takes a whole lot. Although attempts are made to consolidate and coordinate monitoring efforts, the lack of centralized governance has caused monitoring methods to be implemented within each technical area’s “silo,” without any means of centralized support. While a great deal of good data is being collected, the lack of centrally-defined roles and responsibilities has resulted in “tribal knowledge” of individual monitoring components, with little or no integration. This paper explains different monitoring areas and analyzes the real problem organizations are facing today by not having a centralized monitoring strategy to administer all of the independent components and new technology of the centralized strategy which is going to make life easier for all administrators. The centralized approach leads to reduced management administration in compared to individual administration, reduced Mean-Time-To-Repair (MTTR) and extended Mean-Time-Between-Failure (MTBF) (i.e.) the time frame between incidents. Having a complete and well documented Information Technology Enterprise Monitoring Strategy allows an organization to improve control of operations and achieve greater operational efficiency.
Network Monitoring
Networks are critical components of any business irrespective of the size of the organization. When network fails, employees cannot communicate with each other because there won’t be email service available. Monitoring to see if network is up or down is not enough for running business efficiently. There is also some Key Performance Indicators (KPI) like bandwidth, network queues, network errors, percentage of errors, packet discard rate to be monitored. There is some freeware network monitoring software available. So enterprises with budget constraints can make use of these freeware software to prevent productivity and revenue loss.
Server Monitoring
Servers are the heart of any business. So server monitoring plays an important role in any organization. Three things are mainly monitored in a server and they are CPU, Memory, and I/O. There is numerous freeware software available and by having a server monitoring tool, there will not be any losses caused by undetected system failures, and more employee satisfaction for reliable systems. In today’s world of virtualized environment (many logical servers carved out of a single physical box), it is becoming more and more complicated and critical to monitor servers.
Database Monitoring
Business will not work without data and the data volume has been increasing drastically over the years so database monitoring has become very critical to any enterprise. Database monitoring gives a comprehensive and systematic approach to everything done in the database.
Today, applications are supported by and communicate with many database instances. To supports all transactions and users, database availability should be maximized and performance problems should be focused. Also, proactive database performance measures are a must. To address these issues, databases are designed with self monitoring tool. So it is enough, if the database administrator uses this tool.
Web Services Monitoring
Applications are becoming more and more service oriented architectures (SOA). Web services can have more number of users than traditional application users. Other websites can also use web services even without human intervention. Both network and systems management monitoring are critical for Web services operations. Things to be monitored are availability, reliability, scalability, and failover.
Storage Monitoring
Two types of problems are common in storage area and they are not having sufficient disk space and performance problems. Free space is probably the number one area to be watched by system administrators. To avoid performance problems, some things like disk utilization, disk total response time, queue length, total throughput, and total bandwidth should be monitored.
Need for centralized monitoring strategy
Having individual component tools and personnel in separate department leads to inefficient way of problem solving. Today, Enterprise IT organizations are under pressure to align corporate and business objectives and maximum availability of composite applications. The composite applications consists of services/functionality that traverse through many components of the infrastructures like web tier, application tier, database tier, server, storage tiers and possibly multiple service calls to internal/external web services. Without monitoring each tiers of the application landscape for its key performance indicators, it would be very difficult to respond to the incidents and analyze the root cause of the incidents. It also increases the mean-time to recover and mean-time between failures of incidents. Without good performance data, IT would be in a pure reactionary mode. They depend on user complaints, rather than the performance monitoring systems. IT operations staff need to evolve from monitoring not just components of the infrastructure, but business service performance, which means “understanding the health and availability of application is requirement to meet the expectations of the business”. The current focus of IT operations is monitoring the business service and reporting the incidents to the application owner, before it is reported by the customers/end-users. IT teams need to move the concepts and technologies of management from planning and engineering into the real-time operation management.
What is Enterprise Monitoring Strategy?
Enterprise Monitoring strategy is a set of standard operating procedures to collect, analyze, predict and report the performance of the infrastructure and applications both pro-actively and reactively to enhance application availability. The main objective of Enterprise Monitoring is to reduce the mean time to repair the incidents and increase the availability of the applications. Typically an incident resolution involves detection time, response time to think through, repair time and recovery time. Incidents cause poor application/service availability and loss of revenue for the company. Here is the expanded incident life cycle:
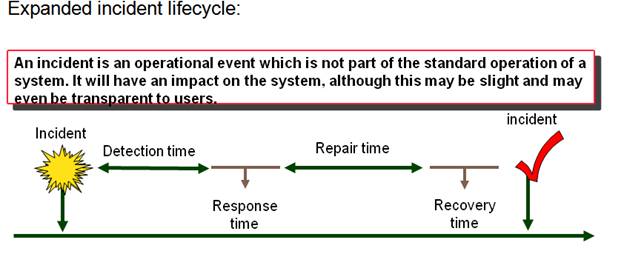
Without good monitoring tools and capturing the Key Performance Indicators from the application and systems, would result in the end user/customers reporting the incidents to the Service Desk. The Service Desk will in-turn engages the technical teams to repair the incidents before the functionality is available for the end-user/customer.
Silo monitoring:
This is the type of monitoring used
in 95% of the organizations. The characteristics of this approach are
·
Individual technical team is responsible
for their monitoring implementation
·
Identifying the key performance
indicators
·
Defining the events and their thresholds
·
Defining the playbook – series of
actions to be taken, when the event arises
·
Feed the events to the single operator
console.
·
Individual teams are not always putting
their best effort to keeping the agents/monitoring tool up and available,
leading to loss of performance data available.
·
Individual technical teams are not able
to see the root cause of the problem by asking other technical teams to look
into the issues. The issue resolution takes longer time. The root cause is not
known. The mean-time to repair the incident takes longer.
Here
is a picture of silo monitoring problems,
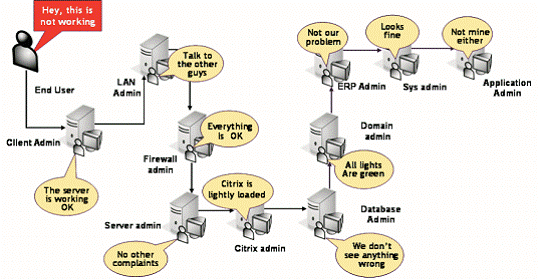
http://www.eginnovations.com/whitepaper/service_management.pdf
The
problem with this approach is, in organizations with roles and responsibility
for
the administrators being specific an attempt to change this model in which everyone operates faces resistance from each silo administrators. Also, setting thresholds set for various key critical business metrics may not be the right one or right alert level. (i.e.) Thresholds can be set very high which result in missing the alert. Lowering threshold would result in false alarm. Adjusting the threshold based on the application is an art than the science. Operational staffs need to go through each alert to figure out which ones needed to be addressed and which should be ignored. False Alerts can make the operators, administrators, engineers and help-desk personnel to chase after a problem that doesn’t exist. Not all silo administrators have access to all monitoring tools. The access is usually team-specific. The performance of the other component cannot be seen to make any real-time decision.
Why centralized enterprise monitoring strategy?
Enterprises are aimed at goals such as
getting better performance at lower price in terms of over-all cost of the
application, higher utilization of expensive resources (servers, storage,
network), application performance not to degrade at times of peak load, and
want to do more and faster application changes. To achieve these goals, enterprise needs a good centralized monitoring strategy. Current IT monitoring efforts at most organizations lack centralization. Organizations are attempting to consolidate all monitoring tools but the monitoring efforts are responsibility of the individual technical teams resulted in the lack of centralized governance which has caused monitoring standards to be implemented within each technical area’s “silo,” without any means of centralized support. While a great deal of good data is being collected, the lack of centrally-defined roles and responsibilities has resulted in “tribal knowledge” of individual monitoring components, with little or no integration. In some cases, excellent and expensive tool sets have become shelf ware as technical teams struggle to implement them in an increasingly complex environment. Monitoring strategy presented in this paper recommends consolidating all of the individual monitoring efforts into a centralized team to get the full benefits of monitoring strategy. Well documented Enterprise Monitoring strategy allows the organization to main a good service level agreement between IT and business partners.
The Centralized Approach
The goal of this approach is to develop a strategy that provides
a centrally-governed monitoring process with clearly defined roles and
responsibilities. Centralized governance
will bridge the silo walls, ensure compatibility or integration of disparate
monitoring tools, and develop clear monitoring objectives. This will ultimately reduce the reactive
nature of current monitoring, and open the door to a sustainable, comprehensive
proactive monitoring process. The characteristics of this approach are
·
Centralized monitoring team need to
defined, who has the sole ownership of installing, configuration and
maintenance of the agents and availability of the monitoring data.
·
Central monitoring team is responsible
for the deployment, configuration, maintenance, and sustainability of monitoring
components. The team would need some
elevated administrator capability to start/stop the agents.
·
Performance data is always available
since it is responsibility of this team rather a part-time for the other
technical teams.
·
This team is better than silo approach
but still it requires the members of the team sufficient technical details to
troubleshoot the performance issue by correlating the events to the key
performance indicators collected and adjusting them on constant basis based on
application functionality or their peak periods.
The
infrastructure which consists of web, application, database, server, network
and storage are monitored by a special technical team responsible for all areas.
In this approach, consistent standards are applied across different silo areas,
interoperability of components is maintained and efforts are focused mainly on
the monitoring system. The issues can be identified before they affect service
continuity and end users. Since the
special team focuses on monitoring services, administrative burden is now off
of silo administrators and they can focus on real value-added work.
The
problem with this approach is the when the event is raised by the application,
the individual team is looking into their events and determining that there is
no problem with their threshold to cause the problem, hence it was deferred to
other technical teams. The same problem of blaming the other teams happens and
not able to find the cause of the performance issue. This raises the need for
the event correlation engine, which can take key performance indicators for
each silo of the infrastructure and determine which silo has highest wait to
identify the right silo that caused the problem infrastructure. Creation of the special team may require
either new-hire personnel or reassigning personnel with individual teams. Efforts should be put to align the new
personnel towards monitoring as a main focus.
This may take longer or more resistance if reassigning was done to form
the special technical team. The special technical team relies on monitors to
inform the respective teams for any problem but it is not ensured that
personnel are constantly watching them actively.
Even
though this approach is a great way of proactive state, the technical team does
not measure or report the gains achieved.
End to End Service Monitoring:
As
with any approach, the centralized approach has its own advantages and
disadvantages.
In
today’s world of dynamic change, the rules for threshold-based alerts can be
inflexible for dynamic environments. For today’s volume and variability of
metrics, it is becoming impossible to use manual rule-based. Also, management of all these thresholds for a
larger organization is really difficult.
The
drawbacks of centralized approach leads to end of end service monitoring called
self learning monitoring which should have the capability to collect the
application performance data along with the systems (silos) key performance
indicators, to indicate when the application performance degrades, which
partition of the silo is causing the biggest wait time. This leads to quicker
problem resolution and reduced the mean-time to repair the incidents. The root
cause of the problem is easy to identify and take correction actions. The
most
significant benefit of this is identifying the cause of complex problems that
involves multiple domains which is essential for any type of root cause
analysis. According to Gartner, “what is needed to solve the
problem is a new technology gaining broad acceptance which Gartner refers to as
“behavior learning” or self-learning technologies. These technologies use
advanced mathematics and analytics to automate performance management in
complex, dynamic environments, often also adding forecasting capabilities.”
(from http://mediaproducts.gartner.com/reprints/netuitive/167307.html).
There are many tools available in the market to do the above mentioned job in a better way. These tools do not replace any human. But these tools give an in-depth analysis of what is going on in the infrastructure, insight in-depth performance of all tiers, gives abstraction of details of each silo, measure services end-to-end. Though these tools are expensive, there will be more returns for the investment. With these tools, it is ensured that silo administrators have more time for productive activities. Since these tools are continuously monitored, these provide a good proactive monitoring strategy (i.e.) indicates of problems before user complaint. According to one of Gartner’s survey, only 5% of the organizations use similar kind of tool and recommends to all other organizations.
Conclusion
With changing role of CIOs, they are restructuring their organizations as internal service providers. They are seeking to manage their environments as services which are made up of integrated systems and components rather than standalone technology silos. Many IT leaders are turning to Information Technology Infrastructure Library (ITIL), an internationally recognized collection of best practices, as a roadmap for service delivery and support. They want to align IT services with current and future needs of the business, improve the quality of the IT services, and efficiently utilize the IT resources. Given the scale and complexity of the problem, many go looking for technology that looks across multiple IT silos to provide the performance analytics and correlation necessary to more rapidly isolate problems. At this point, many silo teams come to the conclusion that they need a better monitoring solution. With end-to-end service monitoring, ITIL practices can be reached easily and efficiently. So companies should start thinking about this end-to-end service monitoring strategy.
This
paper gives an overview of the current situation (from my personal work
experience) in most of the organizations, need for centralized strategy and the
ways to achieve the strategy. It does
not go into details of the strategies. Companies should look into it deeply
before taking decisions.
References
http://technet.microsoft.com/en-us/library/bb124098(EXCHG.65).aspx
http://whitepapers.techrepublic.com.com/abstract.aspx?docid=1152437&tag=content;leftCol
http://www.metron-athene.com/reference/case_studies/index.html
http://www.metron-athene.com/athene/index.html
http://www.cmg.org/measureit/issues/ - mit23/m_23_2.html, mit61/m_61_7.html, mit58/m_58_14.html, mit55/m_55_4.html, mit47/m_47_9.html, mit42/m_42_3.html, mit23/m_23_3.html
http://www.cmg.org/proceedings/1987/87INT070.pdf
Performance Solutions: A Practical Guide to Creating Responsive, Scalable Software. Dr. Connie Smith, Dr. Lloyd Williams, Addison-Wesley Press
http://www.infosysblogs.com/sap/enterprise_performance_management/
http://www2.sys-con.com/ITSG/virtualcd/WebServices/archives/0210/sadwami/index.html
http://mediaproducts.gartner.com/reprints/netuitive/167307.html
White Papers
http://my.gartner.com/portal/server.pt?open=512&objID=260&mode=2&PageID=3460702&resId=1217737&ref=QuickSearch&sthkw=IT+monitoring – Tools Alone Won’t Enable Proactive Management of IT operations
http://www.eginnovations.com/whitepaper/service_management.pdf - A collaborative Approach Accelerates the Transition from Silo Management to True Service Management
http://www.netuitive.com/resource-center - Virtual Data Center Management Challenges
http://www.netuitive.com/resource-center
- The Path to Proactivity : Netuitive Customer
Value Study
http://www.netuitive.com/resource-center
- Taking the Guesswork Out of ITIL
http://www.gartner.com/DisplayDocument?id=1203613
– Gartner’s Business Activity Monitoring and Business Service Management Are
Different
http://www.eginnovations.com/whitepaper/choosing-whitepaper.pdf
- Choosing a Monitoring System for your IT Infrastructure?