
What good are bits, bytes, and a
handful of coins?
Can they help consumers take informed responsibility for risks
in everyday life?
Might jurors assess the significance of DNA evidence with them
as well?
That's only the beginning of what
surprisal-based
information
measures are doing today.
Clues to the big picture are hiding in
the table below, which connects bits of surprisal to a series of increasingly
unlikely events...
|
situation
|
probability p = 1/2#bits
|
surprisal #bits = ln2[1/p]
|
|
one equals one
|
1
|
0 bits
|
|
wrong guess on a 4-choice question
|
3/4
|
ln2[4/3] ~0.415 bits
|
|
correct guess on true-false question
|
1/2
|
ln2[2] =1 bit
|
|
correct guess on a 4-choice question
|
1/4
|
ln2[4] =2 bits
|
|
seven on a pair of dice
|
6/62 =1/6
|
ln2[6] ~2.58 bits
|
|
snake-eyes on a pair of dice
|
1/62 =1/36
|
ln2[36] ~5.17 bits
|
|
random character from the 8-bit ASCII set
|
1/256
|
ln2[28] =8 bits =1 byte
|
|
N heads on a toss of N coins
|
1/2N
|
ln2[2N] =N bits
|
|
harm from a smallpox vaccination
|
~1/1,000,000
|
~ln2[106] ~19.9 bits
|
|
win the UK Jackpot lottery
|
1/13,983,816
|
~23.6 bits
|
|
RGB monitor choice of one pixel's color
|
1/2563 ~5.9×10-8
|
ln2[28*3] =24 bits
|
|
gamma
ray burst mass extinction event TODAY!
|
<1/(109*365) ~2.7×10-12
|
hopefully >38 bits
|
|
availability to reset 1 gigabyte of random access memory
|
1/28E9 ~10-2.4E9
|
8×109 bits ~7.6×10-14 J/K
|
|
choices for 6×1023 Argon atoms in a 24.2L box at 295K
|
~1/21.61E25 ~10-4.8E24
|
~1.61×1025 bits ~155 J/K
|
|
one equals two
|
0
|
∞ bits
|
Something that is certain has a probability of one. No surprisal there. As p decreases from one to zero, surprisal goes from zero to infinity but less quickly than one might imagine. Not even a bit of surprisal is associated with happenings having a better than 50:50 chance. One bit of surprisal (only) is associated with a wild guess of the correct answer to a true-false question. Blind guessing of the correct answer to a 4-choice question has 2 bits of surprisal, something with a probability of only p=1/16 has 4 bits of surprisal, p=1/256 means 8 bits of surprisal, p=1/16,777,216 means 24 bits of surprisal, etc.
| Mnemonic | Range |
| probability p = 1/2#_of_bits_of_surprisal | 0 < p < 1 |
Thus a bit of surprisal is what you feel after "calling heads" on a coin toss, when the coin lands with heads up! Surprisal is two bits when you throw heads on two of two coins at once. Three bits of surprisal (heads up on three of three coins) is starting to feel respectable. Twenty-four bits of surprisal, on the other hand, is closer to what you experience when winning the lottery. Thus surprisal reduces the probability of an extremely rare event to a quantity of more manageable size.
To refine your taste for surprisals, try the following experiment.
Toss
a single coin a few times, each time trying to predict which
side of the coin will land facing up. The predictions (of
ordinary folk, at least) are often wrong. That pleasant
surprise we feel when our prediction comes true (after some practice)
is associated with one bit of surprisal, as defined
above. Next, toss two coins. Occasionally both coins will
land "heads up", and the surprisal associated with that
happening is two bits. Now imagine (or sample) the surprisal
associated with three coins landing "heads up", or four, or
ten. The twenty bits of surprisal associated with
throwing "heads" on
twenty coins on the first try will be better appreciated after
you've tossed those twenty coins hundreds of thousands of
times, without finding all heads up even once. Thus a few
coins in your pocket can give you a feel for what a given
amount of surprisal means, anytime you need a reminder.
|
The equation above tells how to calculate probability given surprisal. To do the inverse (i.e. to calculate surprisal in bits given probability) you can use a calculator to try different bit values in the equation p = 1/2#bits until you get the correct probability, or you can use the logarithmic relations: s = ln2[1/p] = ln[1/p]/ln[2]. Thus in gambling, over 5 bits (~ln2[36]) of surprisal are involved in throwing "snake eyes" with two six-sided die, while a throw of "seven" or "craps" is only half as surprising (s = ln2[6]). Since "snake eyes" has twice the surprisal of "craps", you're as likely to throw snake eyes in one throw of a pair of dice as to throw seven twice in two.

Surprisal can also be useful in assessing risk. In fact, consumers can make informed decisions on taking a given risk by considering the chance that tossing an appropriate handful of coins will (or will not) result in all heads. For example, suppose you plan an action that will reduce the surprisal of you catching smallpox to 16 bits (like that of throwing 16 heads on the first throw of 16 coins). Still not very likely. But if the surprisal of dying from smallpox is only 2 bits (i.e. probability = 1/22 = 1/4), then you might consider getting a vaccination to protect you as long as the surprisal of harm from the vaccination is greater than that of getting done in by smallpox (16+2=18 bits). In practice the surprisal of harm from the vaccine might be closer to 20 bits. The odds of something bad happening either way are tiny, but this simple calculation would let you take informed responsibility for whichever choice you make.
Thus we should perhaps encourage newsmedia to provide surprisal estimates, instead of just telling us that "there's a small chance" of something bad or good happening given the large difference between something with a few bits of surprisal (say 3 heads on 3 coins) and something with more than a dozen bits of surprisal. The risks of: "shaving with an electric razor" versus "walking under a power line", or "eating an apple" versus "smoking a cigarette", might thus routinely be put into context. Likewise use of surprisals in communicating and monitoring risks to medical patients, so that decisions about actions with a small chance of dire outcomes are as informed as possible, might also reduce the costs of medical malpractice in the long run by making the need for legal redress less frequent. These tools could further help customers of the airline and insurance industries clarify the meaning of the choices they make.


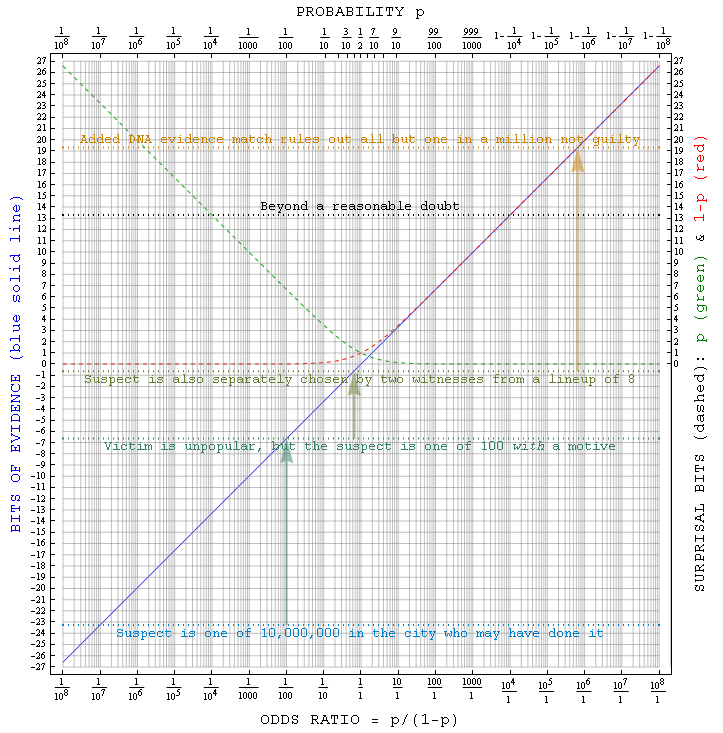
Although surprisals are quite useful when we are talking about things that are unlikely to happen, a similar measure is oft needed for assessing likely true-false hypotheses such as the guilt of someone suspected of a misdeed. A simple but robust measure of evidence for such hypotheses, designed to accomodate new information as it comes in (additively if new bits of evidence are independent), turns out to be the surprisal that a hypothesis is false minus the surprisal that it is true (cf. the figure at left plus items 7 and 9 here). The resulting mnemonic for this evidence in bits (ebits) becomes "odds ratio" = 2ebits. Thus "ebits" is just the binary-log version of good-old racetrack odds. It goes to zero when the odds of something are 50:50, and to negative and positive extremes slowly (like surprisal) as the probability approaches 0 or 1. An ebit of evidence for a proposition's truth means that it has 2:1 odds, two ebits means 4:1 odds, three ebits 8:1 odds, etc.
Thus surprisal differences (like ebits) can help assess the credibility of true-false assertions about the world around. For example, they are a potentially useful element of Bayesian* jurisprudence programs dedicated to development of objective tools for juries to work with in cases when the information they have can (like DNA evidence) be put into quantitative form. As you can see from the plot at right, the meanings of "innocent until proven guilty" and "reasonable doubt" in ebits dovetail seamlessly with their common-sense usage. Such surprisal measures are conceptually accessible to most citizens (at least providing an alternate visualization), and are adaptable to different levels of proof e.g. in civil versus criminal trials. However, they leave entirely up to human judgement whether the correct true-false question is being asked to begin with. It is likely that the quantitative modeling of individual culpability in the face of evidence, including the weighing of question alternatives, may be put onto an even more solid footing in days ahead via more general net-surprisal (KL-information) measures whose application development e.g. in ecology is already underway. For the time being those techniques are not yet ready for nonspecialists, and vice versa.Here you'll find more on the relevance of surprisal measures to: